商机详情 -
惠山区购买智能推荐使用方法
数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示三个步骤。数据准备是从相关的数据源中选取所需的数据并整合成用于数据挖掘的数据集;规律寻找是用某种方法将数据集所含的规律找出来;规律表示是尽可能以用户可理解的方式(如可视化)将找出的规律表示出来。数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等。近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以使用,并且迫切需要将这些数据转换成有用的信息和知识。数据挖掘的对象可以是任何类型的数据源。可以是关系数据库,此类包含结构化数据的数据源;惠山区购买智能推荐使用方法

粗糙集法粗糙集法也称粗糙集理论,是由波兰数学家Z Pawlak在20世纪80年代初提出的,是一种新的处理含糊、不精确、不完备问题的数学工具,可以处理数据约简、数据相关性发现、数据意义的评估等问题。其优点是算法简单,在其处理过程中可以不需要关于数据的先验知识,可以自动找出问题的内在规律;缺点是难以直接处理连续的属性,须先进行属性的离散化。因此,连续属性的离散化问题是制约粗糙集理论实用化的难点。粗糙集理论主要应用于近似推理、数字逻辑分析和化简、建立预测模型等问题。惠山区购买智能推荐使用方法可以把此步骤分为四个部分:选择变量,选择记录,创建新变量,转换变量。

5:Support Vector Machine(支持向量机SVM)SVM就是想找一个分类得好”的分类线/分类面(近的一些两类样本到这个”线”的距离远)。这个没具体实现过,上次听课,那位老师自称自己实现了SVM,敬佩其钻研精神。常用的工具包是LibSVM、SVMLight、MySVM。6:EM(期望化)这个我认为就是假设数据时由几个高斯分布组成的,所以就是要求几个高斯分布的参数。通过先假设几个值,然后通过反复迭代,以期望得到的拟合。7:Apriori这个是做关联规则用的。不知道为什么,一提高关联规则我就想到购物篮数据。这个没实现过,不过也还要理解,它就是通过支持度和置信度两个量来工作,不过对于Apriori,它通过频繁项集的一些规律(频繁项集的子集必定是频繁项集等等啦)来减少计算复杂度。
数据挖掘的对象可以是任何类型的数据源。可以是关系数据库,此类包含结构化数据的数据源;也可以是数据仓库、文本、多媒体数据、空间数据、时序数据、Web数据,此类包含半结构化数据甚至异构性数据的数据源。 [4] 发现知识的方法可以是数字的、非数字的,也可以是归纳的。被发现的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等。在实施数据挖掘之前,先制定采取什么样的步骤,每一步都做什么,达到什么样的目标是必要的,有了好的计划才能保证数据挖掘有条不紊地实施并取得成功。很多软件供应商和数据挖掘顾问公司投提供了一些数据挖掘过程模型,来指导他们的用户一步步地进行数据挖掘工作。比如,SPSS公司的5A和SAS公司的SEMMA。在实际应用中,需要进一步了解错误的类型和由此带来的相关费用的多少。
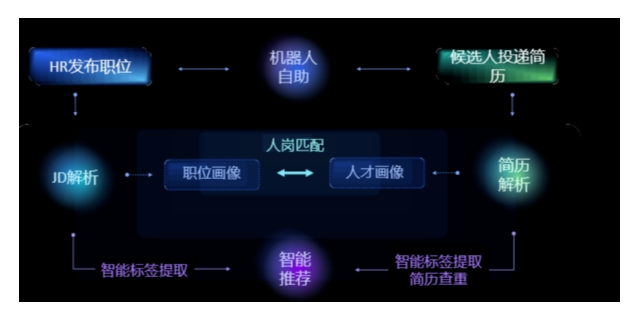
步骤分布式数据挖掘包括以下几个步骤: [1] (1)剖分待挖掘数据成P个子集,P为可用的处理器个数,并把每个数据子集发送到各个处理器;(2)每个处理器运行数据挖掘算法于其局部数据子集,处理器可以运行不同的数据挖掘算法;(3)组合各个数据挖掘算法发现的局部知识成全局、一致的发现知识。研究内容在分布式数据挖掘中有4 种关键技术:数据集中、并行数据挖掘、知识吸收和分布式软件引擎。分布式数据挖掘的研究主要包括分布式数据挖掘算法和分布式数据挖掘体系结构的研究2 个方面.当前已经出现不少分布式和并行的数据挖掘算法, 如并行挖掘关联规则的算法CD (count distribution)、DD (Data distribution),以及PDM 等。缺点是需要的参数太多,编码困难,一般计算量比较大。徐州好的智能推荐厂家供应
连续属性的离散化问题是制约粗糙集理论实用化的难点。惠山区购买智能推荐使用方法
(2)提高可可扩展性。由于用户的应用环境是不断变化的,因此可扩展性对于数据挖掘系统来说非常重要,系统应该支持多种数据源的挖掘以及挖掘算法的可扩展性,允许用户根据需要加入新的算法。(3)与特定行业应用相结合。随着应用环境的发展,通用的数据挖掘系统已越来越不能满足用户的需要,用户如果不了解挖掘算法的特性就很难得出好的模型,因此数据挖掘系统应该和特定的应用紧密结合起来, 为该应用领域提供一个完整的解决方案。4) 遵循统一标准。尽管目前数据挖掘还没有形成一套完整的业界标准, 但已出现了一些标准, 如数据挖掘过程标准CRISP DM、预言模型交换标准PMML和Microsoft的OLE DB for DM。遵循统一标准的数据挖掘系统间可以方便地实现挖掘算法和模型的共享。惠山区购买智能推荐使用方法
江苏巨量指数信息科技有限公司是一家有着先进的发展理念,先进的管理经验,在发展过程中不断完善自己,要求自己,不断创新,时刻准备着迎接更多挑战的活力公司,在江苏省等地区的数码、电脑中汇聚了大量的人脉以及**,在业界也收获了很多良好的评价,这些都源自于自身的努力和大家共同进步的结果,这些评价对我们而言是比较好的前进动力,也促使我们在以后的道路上保持奋发图强、一往无前的进取创新精神,努力把公司发展战略推向一个新高度,在全体员工共同努力之下,全力拼搏将共同江苏巨量指数信息科技供应和您一起携手走向更好的未来,创造更有价值的产品,我们将以更好的状态,更认真的态度,更饱满的精力去创造,去拼搏,去努力,让我们一起更好更快的成长!