商机详情 -
宿迁使用智能推荐调试
这也就是约翰·内斯伯特( John Nalsbert)称为的“信息丰富而知识贫乏”窘境。因此,人们迫切希望能对海量数据进行深入分析,发现并提取隐藏在其中的信息,以更好地利用这些数据。但以数据库系统的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势,更缺乏挖掘数据背后隐藏知识的手段。正是在这样的条件下,数据挖掘技术应运而生。数据的类型可以是结构化的、半结构化的,甚至是异构型的。发现知识的方法可以是数学的、非数学的,也可以是归纳的。终被发现了的知识可以用于信息管理、查询优化、决策支持及数据自身的维护等。源于高性能(并行)计算的技术在处理海量数据集方面常常是重要的。宿迁使用智能推荐调试
数据源层为了提高数据的一致性和完整性,进行数据挖掘前首先应将分散存储在多个数据源中的数据通过数据清理和数据集成等预处理操作集成到一个统一的数据库/ 数据仓库中。为了提高系统的可扩展性,屏蔽数据源采用的具体数据库产品,数据库接口应该采用ODBC、JDBC或OLE DB等技术,以便于更改数据源。赵志宏、钱卫宁等分别提出了基于数据仓库和大规模数据库的数据挖掘系统框架及其应用。 [1] 数据库可以通过4种形式集成到数据挖掘系统中:无藕合的,松藕合的,半松藕合的和紧藕合的。理想的是紧藕合方式,即通过把数据挖掘查询优化成循环的数据挖掘和检索过程从而将2者结合起来,这样可以充分利用数据库所具有的查询、汇总等数据处理功能,减少数据挖掘系统开发负担,提高系统的效率。Rosa Meo提出了一种使用数据挖掘语言Mine Rul e 实现与数据库紧藕合的数据挖掘系统框架。锡山区品牌智能推荐私人定做需要数据库系统提供有效的存储、索引和查询处理支持。

(5) 数据变换:通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。对于有些实数型数据,通过概念分层和数据的离散化来转换数据也是重要的一步。(6) 数据挖掘过程:根据数据仓库中的数据信息,选择合适的分析工具,应用统计方法、事例推理、决策树、规则推理、模糊集、甚至神经网络、遗传算法的方法处理信息,得出有用的分析信息。(7) 模式评估:从商业角度,由行业来验证数据挖掘结果的正确性。(8) 知识表示:将数据挖掘所得到的分析信息以可视化的方式呈现给用户,或作为新的知识存放在知识库中,供其他应用程序使用。
决策树方法决策树是一种常用于预测模型的算法,它通过将大量数据有目的分类,从中找到一些有价值的,潜在的信息。它的主要优点是描述简单,分类速度快,特别适合大规模的数据处理。有影响和早的决策树方法是由quinlan提出的的基于信息熵的id3算法。它的主要问题是:id3是非递增学习算法;id3决策树是单变量决策树,复杂概念的表达困难;同性间的相互关系强调不够;抗噪性差。针对上述问题,出现了许多较好的改进算法,如 schlimmer和fisher设计了id4递增式学习算法;钟鸣,陈文伟等提出了ible算法等。分析的目的是找到对预测输出影响的数据字段,和决定是否需要定义导出字段。

粗集方法粗集理论是一种研究不精确、不确定知识的数学工具。粗集方法有几个优点:不需要给出额外信息;简化输入信息的表达空间;算法简单,易于操作。粗集处理的对象是类似二维关系表的信息表。但粗集的数学基础是论,难以直接处理连续的属性。而现实信息表中连续属性是普遍存在的。因此连续属性的离散化是制约粗集理论实用化的难点。覆盖正例排斥反例方法它是利用覆盖所有正例、排斥所有反例的思想来寻找规则。首先在正例中任选一个种子,到反例中逐个比较。与字段取值构成的选择子相容则舍去,相反则保留。按此思想循环所有正例种子,将得到正例的规则(选择子的合取式)。比较典型的算法有michalski的aq11方法、洪家荣改进的aq15方法以及他的ae5方法。目前,数据挖掘的算法主要包括神经网络法、决策树法、遗传算法、粗糙集法、模糊集法、关联规则法等。宿迁高科技智能推荐风格
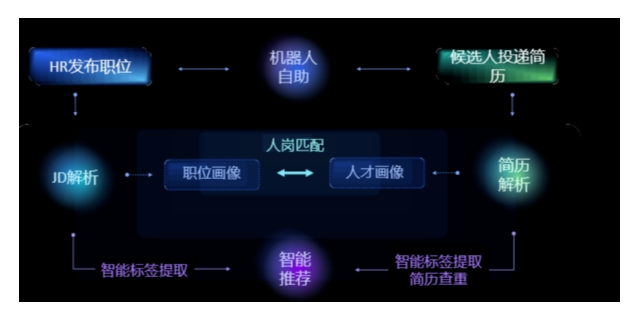
在开始知识发现之前的也是重要的要求就是了解数据和业务问题。宿迁使用智能推荐调试
步骤分布式数据挖掘包括以下几个步骤: [1] (1)剖分待挖掘数据成P个子集,P为可用的处理器个数,并把每个数据子集发送到各个处理器;(2)每个处理器运行数据挖掘算法于其局部数据子集,处理器可以运行不同的数据挖掘算法;(3)组合各个数据挖掘算法发现的局部知识成全局、一致的发现知识。研究内容在分布式数据挖掘中有4 种关键技术:数据集中、并行数据挖掘、知识吸收和分布式软件引擎。分布式数据挖掘的研究主要包括分布式数据挖掘算法和分布式数据挖掘体系结构的研究2 个方面.当前已经出现不少分布式和并行的数据挖掘算法, 如并行挖掘关联规则的算法CD (count distribution)、DD (Data distribution),以及PDM 等。宿迁使用智能推荐调试
江苏巨量指数信息科技有限公司是一家有着雄厚实力背景、信誉可靠、励精图治、展望未来、有梦想有目标,有组织有体系的公司,坚持于带领员工在未来的道路上大放光明,携手共画蓝图,在江苏省等地区的数码、电脑行业中积累了大批忠诚的客户粉丝源,也收获了良好的用户口碑,为公司的发展奠定的良好的行业基础,也希望未来公司能成为*****,努力为行业领域的发展奉献出自己的一份力量,我们相信精益求精的工作态度和不断的完善创新理念以及自强不息,斗志昂扬的的企业精神将**江苏巨量指数信息科技供应和您一起携手步入辉煌,共创佳绩,一直以来,公司贯彻执行科学管理、创新发展、诚实守信的方针,员工精诚努力,协同奋取,以品质、服务来赢得市场,我们一直在路上!