商机详情 -
南京怎样数据处理要求
在数据可视化部分,需要对数据的计算结果进行分析和展现,有BIEE,Microstrategy,Yonghong的Z-Suite等工具。数据处理的软件有EXCEL MATLAB Origin等等,当前流行的图形可视化和数据分析软件有Matlab,Mathmatica和Maple等。这些软件功能强大,可满足科技工作中的许多需要,但使用这些软件需要一定的计算机编程知识和矩阵知识,并熟悉其中大量的函数和命令。而使用Origin就像使用Excel和Word那样简单,只需点击鼠标,选择菜单命令就可以完成大部分工作,获得满意的结果。大数据时代,需要可以解决大量数据、异构数据等多种问题带来的数据处理难题,Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统 Hadoop Distributed File System,HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上。而且它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。数据处理是从大量的原始数据抽取出有价值的信息,即数据转换成信息的过程。南京怎样数据处理要求
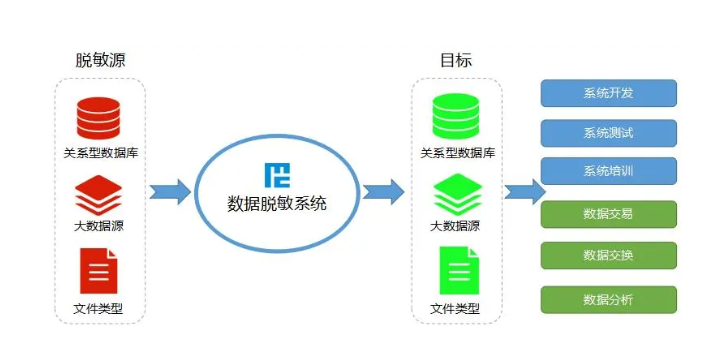
采集在大数据的采集过程中,其主要特点和挑战是并发数高,因为同时有可能会有成千上万的用户来进行访问和操作,比如火车票售票网站和淘宝,它们并发的访问量在峰值时达到上百万,所以需要在采集端部署大量数据库才能支撑。并且如何在这些数据库之间进行负载均衡和分片的确是需要深入的思考和设计。统计/分析统计与分析主要利用分布式数据库,或者分布式计算集群来对存储于其内的大量数据进行普通的分析和分类汇总等,以满足大多数常见的分析需求,在这方面,一些实时性需求会用到EMC的GreenPlum、Oracle的Exadata,以及基于MySQL的列式存储Infobright等,而一些批处理,或者基于半结构化数据的需求可以使用Hadoop。统计与分析这部分的主要特点和挑战是分析涉及的数据量大,其对系统资源,特别是I/O会有极大的占用。南京怎样数据处理要求数据转换:把信息转换成机器能够接收的形式。
如测绘制图管理、仓库管理、财会管理、交通运输管理,技术情报管理、办公室自动化等。在地理数据方面既有大量自然环境数据(土地、水、气候、生物等各类资源数据),也有大量社会经济数据(人口、交通、工农业等),常要求进行综合性数据处理。故需建立地理数据库,系统地整理和存储地理数据减少冗余,发展数据处理软件,充分利用数据库技术进行数据管理和处理。数据处理用计算机收集、记录数据,经加工产生新的信息形式的技术。数据指数字、符号、字母和各种文字的**。数据处理涉及的加工处理比一般的算术运算要***得多。
②根据数据处理时间的分配方式区分,有批处理方式、分时处理方式和实时处理方式。③根据数据处理空间的分布方式区分,有集中式处理方式和分布处理方式。④根据计算机**处理器的工作方式区分,有单道作业处理方式、多道作业处理方式和交互式处理方式。数据处理对数据(包括数值的和非数值的)进行分析和加工的技术过程。包括对各种原始数据的分析、整理、计算、编辑等的加工和处理。比数据分析含义广。随着计算机的日益普及,在计算机应用领域中,数值计算所占比重很小,通过计算机数据处理进行信息管理已成为主要的应用。数据计算:进行各种算术和逻辑运算,以便得到进一步的信息。

商务网站有关商务网站的数据处理:由于网站的访问量非常大,在进行一些专业的数据分析时,往往要有针对性的数据清洗,即把无关的数据、不重要的数据等处理掉。接着对数据进行相关分分类,进行分类划分之后,就可以根据具体的分析需求选择模式分析的技术,如路径分析、兴趣关联规则、聚类等。通过模式分析,找到有用的信息,再通过联机分析(OLAP)的验证,结合客户登记信息,找出有价值的市场信息,或发现潜在的市场 [1] 。数据处理是从大量的原始数据抽取出有价值的信息,即数据转换成信息的过程。主要对所输入的各种形式的数据进行加工整理,其过程包含对数据的收集、存储、加工、分类、归并、计算、排序、转换、检索和传播的演变与推导全过程。而数据库技术就是针对该需求目标进行研究并发展和完善起来的计算机应用的一个分支。建邺区网络数据处理概况
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。南京怎样数据处理要求
挖掘与前面统计和分析过程不同的是,数据挖掘一般没有什么预先设定好的主题,主要是在现有数据上面进行基于各种算法的计算,从而起到预测的效果,从而实现一些高级别数据分析的需求。比较典型算法有用于聚类的K-Means、用于统计学习的SVM和用于分类的NaiveBayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于挖掘的算法很复杂,并且计算涉及的数据量和计算量都很大,还有,常用数据挖掘算法都以单线程为主 [2] 。南京怎样数据处理要求
南京红袋鼠大数据科技有限公司在同行业领域中,一直处在一个不断锐意进取,不断制造创新的市场高度,多年以来致力于发展富有创新价值理念的产品标准,在江苏省等地区的商务服务中始终保持良好的商业口碑,成绩让我们喜悦,但不会让我们止步,残酷的市场磨炼了我们坚强不屈的意志,和谐温馨的工作环境,富有营养的公司土壤滋养着我们不断开拓创新,勇于进取的无限潜力,南京红袋鼠大数据科技供应携手大家一起走向共同辉煌的未来,回首过去,我们不会因为取得了一点点成绩而沾沾自喜,相反的是面对竞争越来越激烈的市场氛围,我们更要明确自己的不足,做好迎接新挑战的准备,要不畏困难,激流勇进,以一个更崭新的精神面貌迎接大家,共同走向辉煌回来!